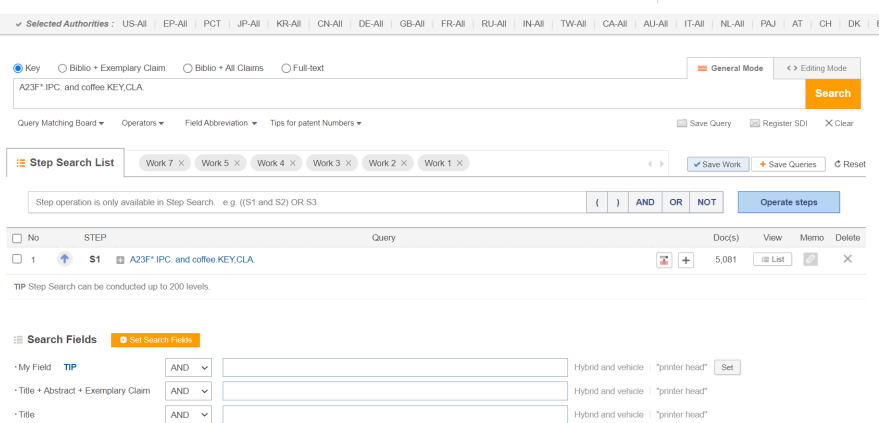
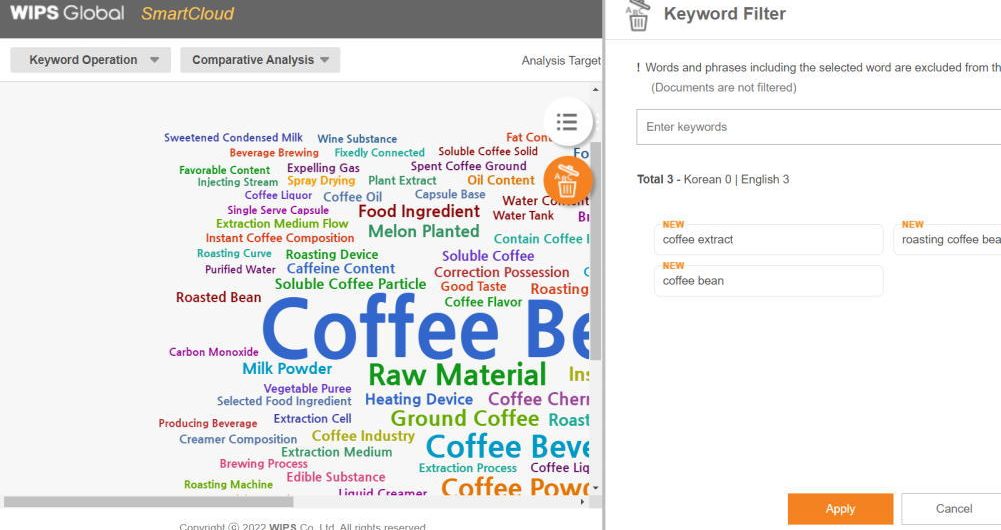
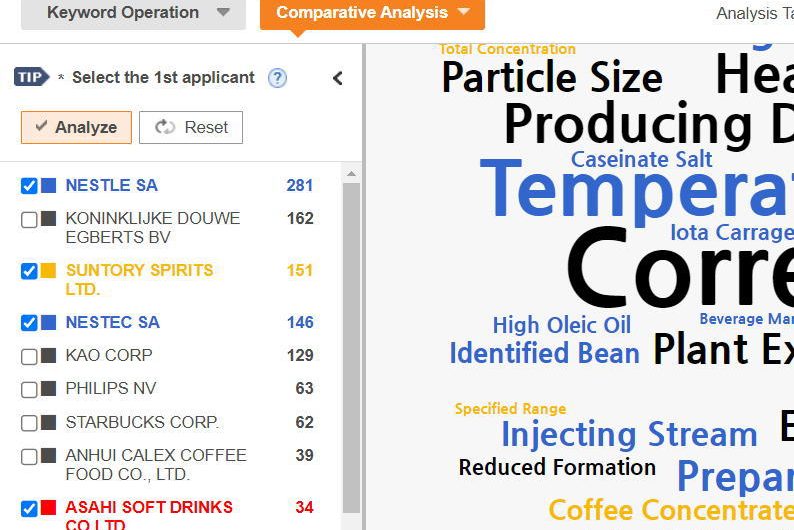
SmartCloudの使い方 多くのテキストマイニングでは、ワードの頻度だけでなく、ワード間の距離等の相関性から分析結果が出力されます。これについて、技術領域を特定して丸で囲った図などが散見されますが、文書クラスタの原理とは異なり、母集団をそのままクラスタリングしているのでは無いため、クラスタ内のノードの関連性について新たな発見するという、難しい分析になります。 SmartCloudは、頻度だけを見せている簡単なマイニングですが、フィルタリングと出願人セグメンテーションの機能が付随しているため、データの傾向性を把握しやすいUIとなっています。 【使い方の簡単な事例~コーヒーに関しての各社の傾向性を観察する】 検索式: A23F*.IPC. and coffee.KEY,CLA.対象期間: 直近の5年間 上記の検索式にて、5,081件のヒットがありましたので、これをSmartCloudで分析します。 当初のワード分析は左の様に何を示しているか、どの様な傾向性があるのか、よく理解できません。 最初に、通常の特許出願であれば、当然に使用されるワードをフィルタして分析の対象外とします。ここでは、cofee bean/コーヒー豆の様な普通に使用される言葉を排除しました。事前にキーワードの頻度表をダウンロードできるので、ここから選択しておいて、入力すると早く処理できます。 次に、出願人をいくつか選んで色付けしながら観察します。必要に応じて再度フィルタを追加しながら観察します。ここでは、ネスレグループを青、サントリーを黄色、スターバックスを赤としました。観察の結果、ネスレグループは加熱方法等のデバイス、サントリーはカフェイン除去等のフレーバ、スターバックスは一人分等のの抽出について興味を持っていると見られました。 この分析が正しいかどうかについては、各ワードをクリックして元の明細書を参照して解釈することになります。そして、これらを繰り返すことで、全体像を把握することができます。