AI-Searchを用いた特許マップ作成の意義
~教師データによる自動分類を特許マップの利点(理解しやすい全体俯瞰)に応用する~
ある母集団をテキストマイニング(文書クラスタ分析)によってセグメント状態を観察する場合には、類似データの集まりを示すため、人間の認知している属性とは異なるクラスタを構成します。例えば、誇張して言えば、ある群は、色彩の赤での集まりに対して、別の群は、形状の四角形での集まりになり、それ自体は正しいクラスタであるものの、特許マップの様に、全体を白と黒と赤とその他、といった色彩の属性のみでクラスタすることは難しいということになります。そこで、この様なクラスタ化をするために、AI-Searchを応用することができます。
(1)想定される分類を定義する
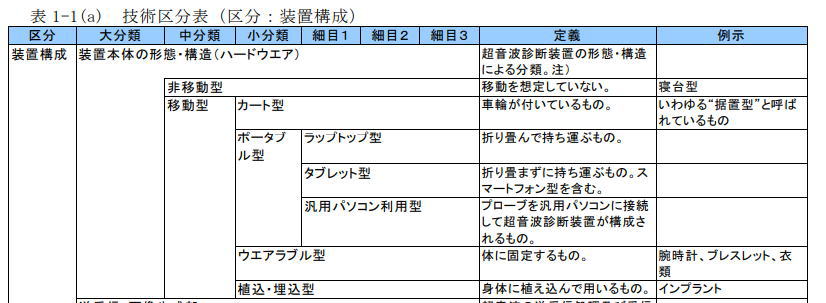
超音波診断装置を例とすると、形態は右図の様に5種類に区分されます。
(2)その分類に入る代表的な特許を見つける
AI-Searchは多言語対応ですので日本の特許で十分です。ここでは、特開2010-119576 寝台型、特開2020-130559 カート型、特開2013-111476 ポータブル、特開2006-122581 身体装着、特表2005-506867 インプラント型をを選んでみました。
(3)それぞれについてAi-Searchで類似文献をサーチする
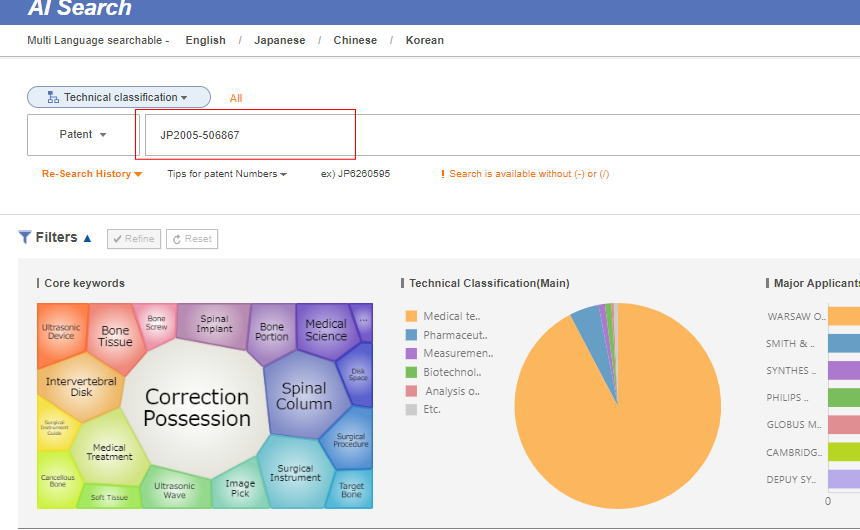
特許番号を入れてサーチボタンを押すと類似度の高いものが選ばれます。ここの段階でも5種類の様々な分析が行えますが、一旦、次のプロセスに移ります。
(4) 一覧文献を選択しMYFOLDERに保存する
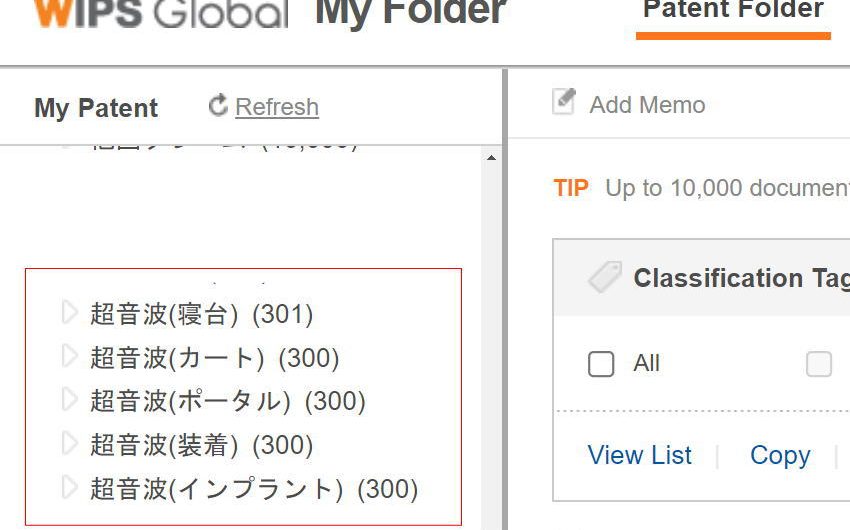
一定の類似度までを目安に選択し、それをMYFOLDERに保存します。あまり類似度が低くなると関係ない特許が増えますが、ここでは手順の説明のみため、簡易的に全件を入れています。
(5) 全てに対してTag付けをし、一つのフォルダにまとめる
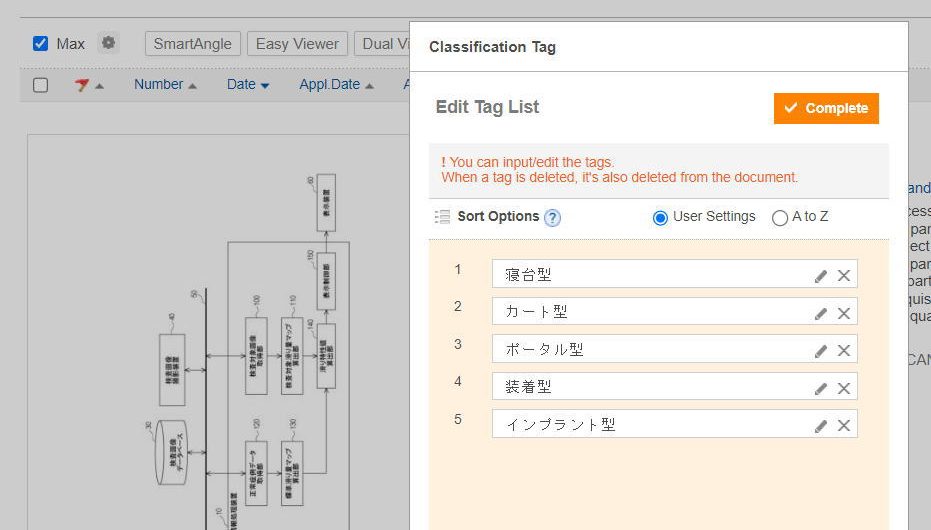
保存した特許に対して分類名のタグを付与し、一つのフォルダにまとめます。(データのマージ)
(6) Tagを用いてマッピングする
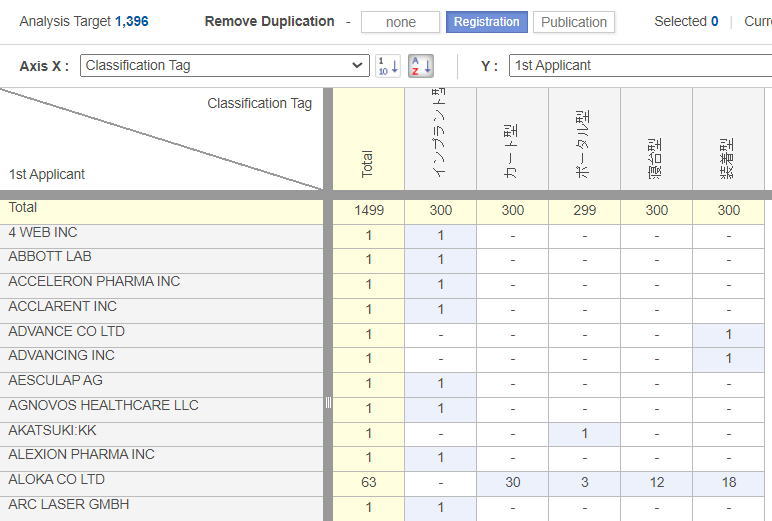

左から、インプラント型、カート型、ポータル型、….このマップから出願人の集中・分散が観察される。
この様に、同じテキストマイニングでも方法を変えることで特許マップと同様な出力を行うことができます。通常のテキストマイニングは、母集団からクラスタリングするのに対して、今回の方法は、特定のコンセプト群を足した集団を作るイメージです。